2020. 1. 2. 15:18ㆍC,C++
출처 : http://www.soen.kr/
SoEn:소프트웨어 공학 연구소
www.soen.kr
6-1 함수의 구성원리
6-1-가. 함수의 정의
프로그램은 함수들로 구성되고 함수들이 순서대로 실행됨으로써 프로그램이 제 기능을 발휘한다. 즉, 함수는 프로그램을 구성하는 단위로서 프로그램의 부품 역할을 한다.
프로그램이 해야 할 일을 각 부품들(=함수)이 나누어 맡으며 그 중에서도 가장 핵심이 되는 함수(=main)의 통제 아래 모든 함수들이 체계적으로 실행되어 전체적으로 프로그램이라는 하나의 완성을 이루는 것이다.

함수는 크게 표준 함수와 사용자 정의 함수로 구분할 수 있다. 표준 함수는 C언어와 함께 작성되어 제공되는 것이며 컴파일러와 함께 배포된다
사용자 정의 함수는 개발자가 필요에 따라 만들어 쓰는 함수이다. 표준 함수들이 모든 기능을 다 제공해 주는 것은 아니므로 프로그램의 목적에 따라 적합한 함수를 만들어 쓸 수 있어야 한다
6-1-나. 함수
함수별로 특정 기능을 담당하도록 프로그램의 기능을 분할해 놓으면 코드의 구조가 만들어지기 때문에 관리하고 재사용하기 편리하다. C언어를 구조적 프로그래밍(Structural Programming) 언어라고 하는 이유가 바로 여기에 있다. 또한 비슷한 작업을 반복적으로 계속 수행할 때는 전담 함수를 만들어 놓고 필요할 때마다 이 함수만 호출하면 되므로 코드의 반복을 방지할 수도 있다. 그래서 함수를 프로그램의 부품이라고 하는 것이다.
6-1-다. 인수
인수(Parameter)는 호출원에서 함수에게 넘겨주는 작업 대상이라고 할 수 있다.
인수는 형식인수와 실인수로 구분되는데 함수의 인수 목록에 나타나는 인수를 형식 인수라고 하며 함수 호출부에서 함수와 함께 전달되는 인수를 실인수라고 한다. 영문으로 된 표준 문서에는 형식 인수를 Parameter로, 실인수를 Argument로 용어를 구분한다.
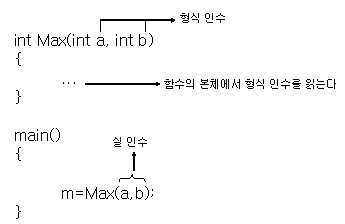
형식 인수는 호출원에서 전달한 실인수값을 잠시 저장하기 위한 임시 저장 장소이므로 어떤 이름이든지 사용해도 상관없다.
6-1-라. return
인수가 호출원으로부터 전달되는 작업 대상이라면 리턴값은 함수가 호출원으로 돌려주는 작업 결과이다.
호출원에서는 타입만 맞다면 함수가 리턴하는 값을 곧바로 사용할 수 있다. 즉, int 타입이 올 수 있는 곳이라면 int 타입을 리턴하는 함수도 항상 올 수 있다.
. 다음 함수 호출도 모두 적법하다.
gotoxy(Max(a,b),Add(c,d));
Add(Add(Add(Add(1,2),3),4),5);
두 번째로 return 문은 결과를 돌려주는 것 외에 함수를 강제 종료시키는 기능을 한다.
main 함수에서 return 문이 사용되면 이것은 곧 프로그램을 끝내라는 명령이 된다. main 함수는 프로그램의 본체이기 때문에 이 함수를 종료하는 것은 곧 프로그램을 종료하는 것과 같다. 그래서 main 함수에서 return문은 exit(0)와 효과가 같다.
6-2. 헤더파일
6-2-가. 함수의 원형
함수의 원형을 이해하기 위해서는 C 컴파일러의 컴파일 방식에 대해 알아야 한다.
프로그래밍 언어는 해석 방식에 따라 인터프리터 방식과 컴파일 방식으로 나누어지는데 컴파일 방식이 훨씬 더 성능이 좋기 때문에 대부분의 언어가 컴파일 방식을 사용한다.
컴파일 방식은 소스를 읽어 기계어로 한꺼번에 번역하는 방식인데 번역을 몇 번에 나누어 하느냐에 따라 1패스, 2패스 등으로 구분된다.
3패스 방식을 채택하는 언어도 있고 디스 어셈블러들은 5패스 방식까지도 사용한다. 언어가 복잡해질수록 패스 수가 늘어나며 사용하는 메모리는 많아지고 컴파일 속도는 떨어진다.
물론 최근의 C컴파일러들은 1패스가 아닌 것들도 있지만 초기의 컴파일러들이 1패스 방식으로 작성되었기 때문에 C표준은 이런 컴파일러를 위해 한 번에 소스를 읽을 수 있는 장치를 마련할 필요가 있었다. 이러한 C의 1패스 방식 때문에 함수의 원형이라는 것이 필요하다.
원칙적으로 함수는 사용되기 전에 미리 그 형태를 컴파일러가 알 수 있도록 해야 하는데 그 방법이 바로 원형(ProtoType)을 선언하는 것이다
6-2-나. 원형의 형식
함수의 원형은 컴파일러에게 함수에 대한 정보를 제공하기 위해 작성한다.
이때 함수의 원형에 적는 형식 인수의 이름은 사실 아무 의미가 없다. int Max(int kkk, int mmm); 이라고 써도 결과는 완전히 동일하다. 왜냐하면 형식인수란 함수의 본체내에서 호출원으로부터 전달된 값을 참조하기 위해 사용하는 것인데 원형 선언은 본체를 가지지 않으며 형식 인수를 사용하지 않기 때문이다.
함수의 원형에서 형식 인수의 이름은 의미가 없기 때문에 형식 인수를 생략하는 간략한 원형 선언 방식도 허용된다. 인수 리스트에서 형식 인수 이름은 빼 버리고 인수의 타입만 적는 방식인데 Max 함수의 간략한 원형은 int Max(int,int);가 된다. 이 원형만으로도 컴파일러는 Max 함수에 대한 모든 정보를 다 알 수 있다.
하지만 최근에는 가급적이면 함수의 원형을 완전하게 적는 것이 더 권장된다. 형식 인수의 이름이 컴파일러에게는 아무 도움이 되지 않지만 함수를 사용하는 사람에게는 도움이 되기 때문이다.
원형에 포함된 형식 인수의 이름은 주석보다 더 좋은 참고 정보가 되므로 가급적이면 인수의 의미를 정확하게 전달할 수 있는 이름을 적어 놓는 것이 좋다.
6-2-다. 헤더파일
printf, scanf같은 표준 함수들도 함수이기 때문에 호출 전 그 원형을 컴파일러가 알 수 있도록 해야 한다.
표준 함수들의 원형은 컴파일러를 만들 때 이미 결정되어 있기 때문에 컴파일러 제작사들이 원형을 미리 작성하여 컴파일러와 함께 배포한다.
이처럼 표준 함수 원형을 미리 작성한 것을 헤더 파일(Header file)이라 하며, stdio.h가 대표적이다.

ex) 두 개 정수 a,b를 입력받아 a의 b승을 구하는 power 함수 작성하기.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#include <stdio.h>
long long power(int a,int b){
int i;
long long c;
c = (long long)a;
if(b == 1) return c;
for(i=2;i<=b;i++){
c = c*a;
}
return c;
}
void main(){
int a,b;
scanf("%d",&a);
scanf("%d",&b);
printf("%lld\n",power(a,b));
}
|
cs |
실행 결과

6-3-라. C++의 참조 호출
. C++은 포인터를 이용하는 방법외에 레퍼런스라는 개념으로 참조 호출을 추가로 지원한다
#include <Turboc.h>
void plusref2(int &a);
void main()
{
int i;
i=5;
plusref2(i);
printf("결과=%d\n",i);
}
void plusref2(int &a)
{
a=a+1;
}
호출부에서는 &i가 아닌 i를 전달하며 함수의 본체에서는 *a를 쓰지 않고 a를 바로 쓴다.
C++의 레퍼런스는 C의 포인터를 사용하는 방법보다는 더 발전된 방법이지만 이것도 엄밀하게 따지면 값 호출이다. 다음에 레퍼런스를 깊게 배워 보면 알겠지만 레퍼런스는 내부적으로 포인터를 흉내낸다. 따라서 레퍼런스를 사용한 참조 호출은 포인터를 흉내내어 참조 호출을 흉내내는 아주 기만적인 참조 호출일 뿐이다.
6-4-가. #include
#include와 같은 명령을 전처리기(PreProcessor)라고 하며 이 외에도 여러 가지 종류의 전처리기가 있다.
전처리기는 말 그대로 "앞서 먼저 처리하는 명령"이라는 뜻인데 컴파일하기 전에 소스를 재작성하는 역할을 한다.
컴파일러가 소스를 읽기 전에 전처리기가 먼저 실행되어 컴파일하기 좋도록 소스의 모양을 정리하는데 전처리기는 코드를 생성하지 않으며 어디까지나 소스를 재구성할 뿐이다.
컴파일 전 단계에서 실행되기 때문에 다소 독특한 제약이 있는데 전처리문은 반드시 한 행을 모두 차지해야 하며 전처리문 뒤에 C 코드를 같이 쓸 수 없다. 프리 포맷의 예외인 셈이다. 단 주석은 코드가 아니므로 전처리문 뒤에 올 수 있다.
#include <stdio.h> int i; // 요렇게 할 수 없다. 단 주석은 가능하다.

#include 명령을 쓰는 대신 헤더 파일의 내용을 복사하여 직접 소스에 붙여 넣어도 결과는 동일하지만 불편할 것이다. #include 명령으로 포함시키면 하나의 헤더 파일을 여러 소스에서 동시에 사용할 수 있으며 소스의 길이가 짧아져 관리하기에도 좋다.
■ #include <file.h> : C에서 제공하는 표준 헤더파일을 포함시키고자 할 때 < > 괄호를 사용한다. < >괄호를 사용하면 표준 헤더 파일 디렉토리에서 지정한 파일을 찾는다.
■ #include "file.h" : 사용자가 직접 작성한 헤더 파일을 포함시키고자 할 때 " "괄호를 사용한다.
. " " 괄호를 사용했더라도 현재 디렉토리에 이 파일이 없으면 표준 헤더 파일 디렉토리도 검색하며 반대로 < > 괄호를 사용했더라도 현재 디렉토리도 같이 검색한다.
포함할 파일이 주 파일과 다른 디렉토리에 있다면 디렉토리 경로를 사용하는 것도 가능하다. 예를 들어 header.h 파일이 주 파일과 같은 레벨의 include라는 별도의 디렉토리에 저장되어 있다거나 주 파일의 부모 디렉토리 아래의 poham 디렉토리에 있다면 다음과 같은 형식으로 포함시키면 된다.

윈도우즈 환경에서 디렉토리 경로를 구분할 때는 역슬레쉬(\) 기호를 사용하지만 #include 문에서는 경로 구분자로 슬레쉬(/)를 사용한다.
6-4-나. #define
기억하기 쉬운 적당한 이름을 주고 실제값을 뒤에 써 주면 되는데 예를 들어 YEAR라는 매크로 상수를 365로 정의하고 싶다면 #define YEAR 365라고 정의하면 된다.
그렇다면 그냥 1200.0을 바로 쓰는 것과 MACH라는 매크로 상수를 정의하여 사용하는 것과는 어떤 차이점이 있을까? 컴파일된 결과는 아무 차이가 없지만 상수에 이름을 붙이면 소스를 읽기가 훨씬 더 쉬워지고 관리하기도 수월해진다.
매크로 이름에는 공백이 들어갈 수 없지만 매크로의 실제값은 공백을 가질 수 있다. #define 전처리문은 매크로를 실제값으로 단순 치환할 뿐이므로 공백이 있건 한글을 사용하건 전혀 상관하지 않는다. 다음은 자주 쓰는 메시지 문자열을 매크로로 정의한 것이다.
#define ERRMESSAGE "똑바로 하란 말이야"
어느 수준으로 매크로 상수를 활용할 것인가는 프로젝트의 성격에 따라 결정하되 나는 개인적으로 일괄적인 수정의 용이함을 위해서는 매크로를 사용하지만 기억의 용이함을 위해서는 사용하지 않는 편이다. 이런 목적이라면 매크로 상수를 쓰는 것 보다는 const나 열거형, 아니면 상수옆에 짧은 주석을 달아 놓는 방법을 더 많이 애용한다.
6-4-다. 매크로 함수
매크로 함수는 #deifne 전처리기를 활용해 함수 흉내를 내는 것이다.
#define dubae(i) i+i;
하지만 위와 같은 매크로 함수 정의는 상당히 위험한 면이 잇다. 무척 간단하지만 #define문이 워낙 단순 무식하고 전처리기 동작이 기계적 치환에 불과하기 때문에 주의할 점이 많다.
1) 매크로 함수 전체식을 괄호로 싸야 함. 연산 우선 순위에 영향을 받지 않기 위해.
2) 매크로 인수들도 개별적으로 괄호로 싸줘야 함.
다음은 아주 적절히 작성된 매크로 함수의 예이다.

'C,C++' 카테고리의 다른 글
| [C] C언어 공부하기 8. 표준 함수 (0) | 2020.01.02 |
|---|---|
| [C] C언어 공부하기 7.지역변수 (0) | 2020.01.02 |
| [C] C언어 공부하기 5.연산자 (0) | 2020.01.02 |
| [C] C언어 공부하기 4. 제어문 (0) | 2019.12.30 |
| [C] C언어 공부하기 3. 변수 (0) | 2019.12.30 |